


¿En qué se parece la Inteligencia Artificial a una ensalada?
El poder de las analogías

Una de las dificultades al explicar la inteligencia artificial, sus conceptos y características, es que puede resultar un tema algo abstracto, especialmente para quienes no están familiarizados con él. Por eso, una estrategia que hemos encontrado efectiva es el uso de analogías.
¿Por qué recurrir a analogías? Básicamente, una analogía establece una relación de semejanza entre elementos que, en principio, son distintos. Al encontrar estos puntos en común, logramos que las personas comprendan mejor el concepto que queremos presentar o explicar.
En el caso de la inteligencia artificial, la analogía que nos ha funcionado especialmente bien —y que ideó Juan Sebastián Sandino— es compararla con el proceso de preparar una ensalada.
¿Cómo lo abordamos entonces?
Empezamos identificando tres elementos o etapas en la preparación de una ensalada.
La primera es la entrada, que corresponde a los ingredientes. Dependiendo del tipo de ensalada que queramos preparar, necesitaremos distintos insumos. Por ejemplo, si se trata de una ensalada de vegetales, podríamos utilizar aguacate, pepino, cebolla y tomate. Si es una ensalada de frutas, los ingredientes serían otros. Lo esencial aquí es mostrar que, para hacer una ensalada, se requieren tanto ingredientes como herramientas básicas, como cuchillos, una ensaladera, etc.
La segunda etapa es lo que llamamos la receta. Se trata de seguir un conjunto de instrucciones que nos indican qué hacer con cada ingrediente: cómo procesarlos, cómo combinarlos, en qué cantidades utilizarlos y cuánto tiempo tomará la preparación. La calidad de los ingredientes y la precisión en seguir la receta son factores clave para obtener el resultado deseado.
Finalmente, llegamos a la salida, que es la ensalada ya preparada según lo que habíamos concebido originalmente. Si contamos con los ingredientes adecuados y seguimos correctamente la receta, obtendremos el plato que queríamos.
Con esto en mente, establecemos una analogía entre la preparación de una ensalada y el funcionamiento de la inteligencia artificial. Dividimos el proceso en tres fases: entrada, donde se encuentran los ingredientes; procesamiento, que equivale a las instrucciones o la receta; y salida, que en este caso sería la ensalada lista para servir.

Ahora, abordamos esta analogía desde la perspectiva del proceso de la inteligencia artificial. En la etapa de entrada, los ingredientes, en el caso de la inteligencia artificial, serían los datos. Aquí es donde enfatizamos su importancia: los datos son el punto de partida. Sin datos adecuados, no hay inteligencia artificial.
Para ilustrarlo, suelo hacer una pregunta a los participantes: ¿Te comerías una ensalada en la que los tomates están sucios? Hasta ahora, el 100% de las personas ha respondido que no. Entonces les digo: Yo tampoco. Esto nos sirve para resaltar la importancia de limpiar y preparar los datos. En cualquier organización o proceso de inteligencia artificial, no basta con recolectar datos; es fundamental curarlos, homogeneizarlos si es necesario y darles el formato adecuado antes de pasar a la siguiente etapa.
En el caso de la ensalada de frutas, el siguiente paso es seguir la receta o las instrucciones. En la inteligencia artificial, este equivalente es el algoritmo. Al final, un algoritmo no es más que un conjunto de instrucciones que determinan qué hacer con los datos y cómo procesarlos. En esta etapa entran en juego las diferentes tareas de la inteligencia artificial: modelos de regresión, clusterización, sistemas de recomendación, entre otros. Cada uno de ellos define la manera en que los datos serán analizados y utilizados.
Para reforzar la analogía, suelo hacer otra pregunta: Si tienes los ingredientes listos para una ensalada de frutas y la receta indica que debes agregar cebolla o ajo, ¿la seguirías al pie de la letra? La mayoría de las personas (hasta ahora) responde que no. Esto nos ayuda a explicar que el algoritmo es clave. Seguir las instrucciones correctas es fundamental.
Luego, pasamos a la salida, que dependerá del modelo empleado. Por ejemplo, si se trata de un modelo de regresión, el resultado será un valor asociado a la relación entre dos o más variables. Si es un modelo de clusterización, mostrará cómo están agrupados los datos para su análisis. Pero, en última instancia, lo que obtenemos es información útil para la toma de decisiones.
En esta etapa culminamos conectando con otro aspecto esencial: si algo no funciona bien en la entrada (es decir, en los datos), o si el algoritmo tiene problemas, como sesgos o una mala estructuración, el resultado final será deficiente. Esto significa que la inteligencia artificial no estará cumpliendo su propósito. Cuando esto ocurre, es necesario revisar qué falló: los datos o el algoritmo.
Por eso, la analogía sigue funcionando tan bien. Así como en una ensalada la calidad de los ingredientes y la precisión de la receta determinan el resultado final, en la inteligencia artificial, la calidad de los datos y el diseño del algoritmo afectan directamente la predicción o la salida generada.
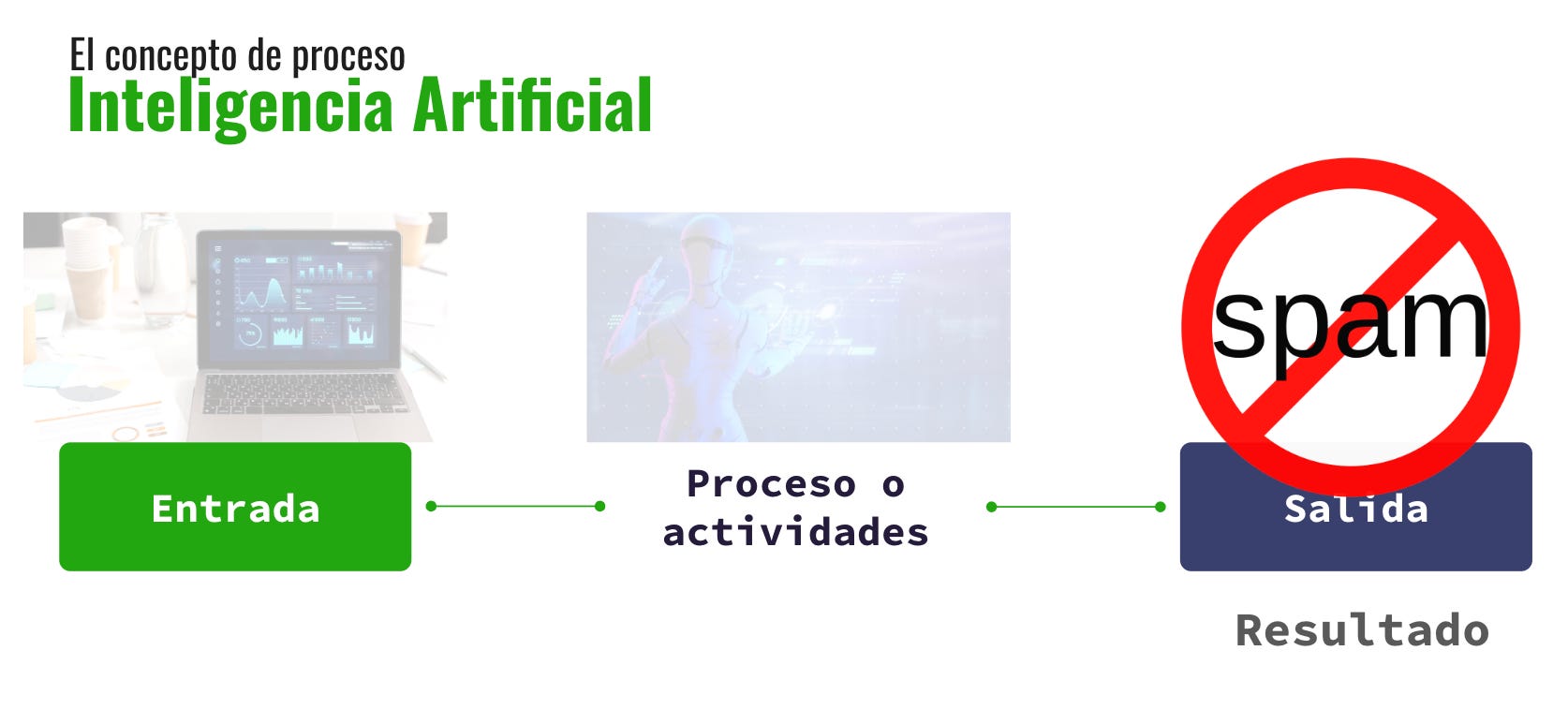
Utilizamos un ejemplo concreto de la aplicación de un algoritmo de inteligencia artificial que todas las personas, de manera consciente o no, usan en su vida cotidiana: las carpetas de spam en el correo electrónico.
Todas las cuentas de correo tienen una carpeta de "correo basura" o "spam". Para ilustrar cómo funciona, explicamos que existen miles, incluso millones de correos electrónicos etiquetados como spam y otros que no lo son. El algoritmo aprende a partir de estos datos: se le indica qué características tienen en común los correos spam y cuáles los distinguen de los correos legítimos. Así, cuando llega un nuevo correo, el algoritmo analiza sus características y, si tiene una alta probabilidad de ser spam, lo envía directamente a la carpeta de correo no deseado.
Sin embargo, es importante recalcar que el algoritmo no es infalible. Su decisión se basa en una predicción probabilística, no en una certeza absoluta. Para hacer esto más tangible, suelo bromear sobre una situación que todos hemos experimentado alguna vez: estamos esperando un correo importante, reclamamos porque no nos lo han enviado, y la otra persona insiste en que sí lo hizo. Al revisar la carpeta de spam, ahí está el correo. Esto demuestra que el algoritmo puede cometer errores y que sus decisiones no siempre son 100% precisas.
Este ejemplo también nos permite introducir el concepto de falsos positivos y falsos negativos. Un falso positivo ocurre cuando el algoritmo identifica como spam un correo legítimo y lo envía a la carpeta de correo no deseado. Un falso negativo, en cambio, sucede cuando un correo que en realidad es spam logra pasar a la bandeja de entrada. Estos errores son inevitables y forman parte de las limitaciones del modelo.
Además, el ejemplo del spam refuerza la estructura básica del proceso de inteligencia artificial, que sigue el mismo esquema de entrada, procesamiento y salida. En este caso, la entrada son los datos: correos electrónicos previamente clasificados como spam o no spam. El proceso es el trabajo del algoritmo, que identifica patrones en los correos para determinar su clasificación. Y la salida es la acción final: enviar el correo a la carpeta de spam o dejarlo en la bandeja de entrada.
Finalmente, en esta sección, hacemos énfasis en la inteligencia artificial generativa, que es la que la mayoría de las personas utiliza actualmente para interactuar con herramientas como ChatGPT, Gemini, Claude, Grok, entre otras.
Para explicarlo, seguimos el mismo enfoque de tres etapas: entrada, procesamiento y salida.
En la entrada, el equivalente sería el prompt o las instrucciones. Aunque no existe una traducción exacta, lo explicamos como aquello que el usuario le indica a la herramienta: lo que quiere que haga, que responda o que analice.
En la fase de procesamiento, entra en juego el modelo de inteligencia artificial en sí, cuyo funcionamiento depende de la empresa que lo haya desarrollado. Por ejemplo, ChatGPT pertenece a OpenAI, Gemini es de Google, Grok es de xAI (la empresa de Elon Musk), entre otros.
En la salida, obtenemos la respuesta generada por la inteligencia artificial según el prompt proporcionado.
También aprovechamos esta sección para resaltar un aspecto clave de la inteligencia artificial generativa: la calidad del resultado depende en gran medida de la calidad de la entrada. Si el prompt no es claro o detallado, la respuesta puede no ser la esperada. Por ejemplo, si quiero que la herramienta genere una tabla pero no lo especifico claramente, es posible que en su lugar me devuelva un párrafo con información en texto.

Además, en la fase de procesamiento, es importante reconocer que estas herramientas tienen limitaciones. Aunque su desempeño es impresionante, no son infalibles. Sus restricciones dependen de la forma en que han sido entrenadas, lo que puede generar sesgos o errores en las respuestas.
Para ilustrarlo, suelo compartir una anécdota personal: en ocasiones, al hacerle una pregunta a ChatGPT, noto que comete un error. Cuando se lo señalo, la propia herramienta reconoce la equivocación y corrige su respuesta. Esto nos ayuda a entender que se trata de un proceso iterativo, donde el usuario puede refinar su interacción para mejorar los resultados.
Sin embargo, en esta sesión no profundizamos demasiado en estos aspectos, ya que en encuentros posteriores abordamos con mayor detalle temas como inteligencia artificial generativa, ingeniería de prompts y el uso avanzado de estas herramientas.
Para finalizar esta sesión, hacemos una recapitulación y enfatizamos un elemento clave: aunque la inteligencia artificial es un concepto complejo, podemos explicarlo de manera didáctica a través de un modelo simplificado basado en tres etapas fundamentales. A lo largo de la sesión, hemos utilizado diferentes ejemplos —la ensalada, la inteligencia artificial y la inteligencia artificial generativa— para ilustrar cómo estas etapas se reflejan en distintos contextos.
Entrada:
En la ensalada, la entrada corresponde a los ingredientes necesarios para su preparación.
En la inteligencia artificial, la entrada son los datos con los que se alimenta el modelo.
En la inteligencia artificial generativa, la entrada es el prompt, es decir, las instrucciones que el usuario proporciona a la herramienta.
Procesamiento:
En la ensalada, el procesamiento se basa en la receta o instrucciones que indican cómo combinar los ingredientes.
En la inteligencia artificial, el procesamiento lo lleva a cabo un modelo o algoritmo, que analiza los datos y genera una predicción o resultado.
En la inteligencia artificial generativa, el procesamiento lo realizan los modelos específicos desarrollados por cada empresa, como los de OpenAI, Google o xAI.
Salida:
En la ensalada, la salida es el plato listo para consumir.
En la inteligencia artificial, la salida suele ser una predicción o un resultado, según el tipo de modelo utilizado.
En la inteligencia artificial generativa, la salida es la respuesta generada por la herramienta, como ChatGPT, Grok, Gemini, entre otras.
Este modelo nos ayuda a visualizar de manera sencilla cómo funciona la inteligencia artificial y qué papel juegan los diferentes elementos en cada etapa del proceso.